
In einem meiner vorhergehenden Beiträge habe ich beschrieben, wie das bei PASS seit mehreren Jahren eingesetzte Managementmodell funktioniert. Nochmals kurz zusammengefasst: Es basiert auf drei Leistungskennzahlen (Produktivität, Kosten und Qualität) und den zugehörigen Messmethoden.
Die Produktivität eines Entwicklungsprozesses wird anhand von Messungen des Entwicklungsumfangs und des dafür benötigten Personalaufwands errechnet. Darüber hinaus wird auch die Qualität gemessen. Nun soll es um die Informationen gehen, die man durch eine zyklische Erhebung von Leistungskennzahlen (Key Performance Indicators, KPIs) über einen längeren Zeitraum hinweg erhält.In einem einzelnen Zyklus des Managementmodells verraten uns die erhobenen KPIs, wie es um Produktivität, Kosten und Qualität zum Zeitpunkt ihrer Erhebung steht – relativ zu einem Bezugswert oder den Kennzahlen anderer Systeme oder Organisationseinheiten. Eine weitere bedeutende Informationsquelle ist jedoch der Verlauf dieser Kennzahlen über mehrere Zyklen hinweg.
Blogserie: Produktivität in der Softwareentwicklung
- Produktivitätssteigerung in der Softwareentwicklung – eine Buchvorstellung
- Neues Buch: Produktivitätssteigerung in der Softwareentwicklung – Teil 2
- Drei Hebel für mehr Produktivität in der Softwareentwicklung
- Produktive Softwareentwicklung erfordert ein Managementmodell
- In der Softwareentwicklung ist jeder Fehler eine Chance
- Produktiver Durchblick: Monitoring in der Softwareentwicklung
Darstellung in zwei Dimensionen: Produktivität und Qualität
In der Praxis der Weiterentwicklung von Softwareprodukten hat es sich bei PASS bewährt, den Verlauf sowohl der Produktivität als auch der Qualität zu verfolgen. Sind Messmethoden etabliert, lässt sich die Produktivität für jedes Release oder auch je Zeitperiode anhand des Entwicklungsumfangs und des dafür benötigten Personalaufwands leicht, manchmal sogar automatisiert errechnen. Als Kennzahl für die Qualität verwenden wir die Anzahl der Produktionsfehler (siehe auch: „In der Softwareentwicklung ist jeder Fehler ist eine Chance“), bereinigt um Ursachen wie falsche Bedienung, neue Anforderungen, Probleme der Betriebsinfrastruktur etc.
Trägt man die regelmäßig erhobenen Messwerte für Produktivität und Qualität in ein einfaches Diagramm ein, werden Auswirkungen zahlreicher Einflüsse erkennbar:
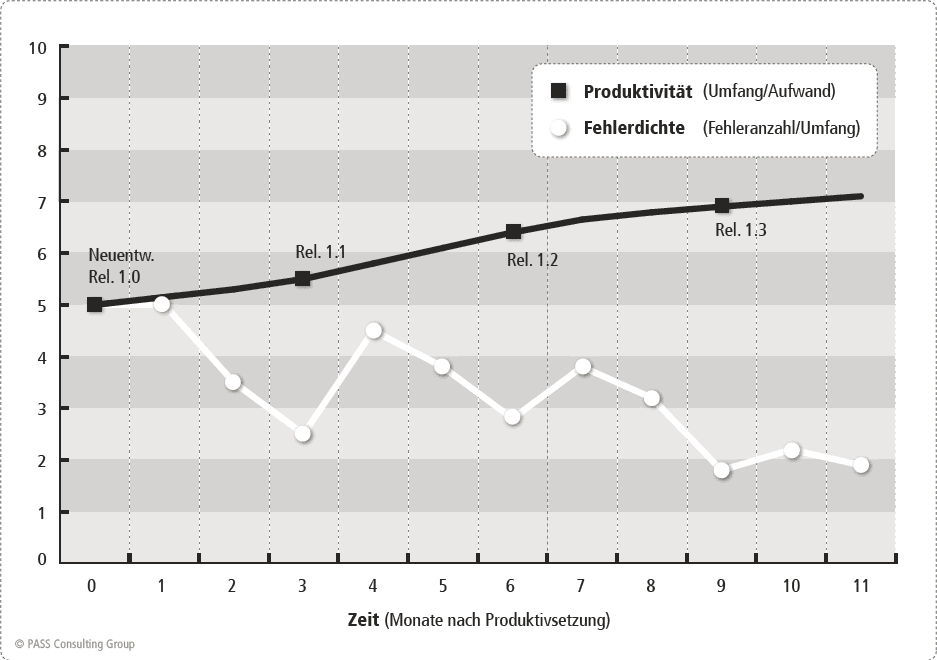
In diesem Fallbeispiel erhöht sich die Produktivität mit jedem neuen Release, das in Produktion gesetzt wird. Das ist ein Indikator dafür, dass das Team bzw. der Shop lernt und sich permanent verbessert. Vielleicht wurden vor Release 1.0 auch Verbesserungsmaßnahmen umgesetzt, deren Wirksamkeit nun durch den Kurvenverlauf verifiziert werden kann. Der Verlauf der Fehlerkurve zeigt, dass die Fehleranzahl nach jedem neuen Release zunächst steigt, was ein „normaler” Effekt ist, dieser Trend sich jedoch nach spätestens einem Monat wieder umkehrt und insbesondere langfristig betrachtet die Anzahl der Produktionsfehler immer geringer wird. Die Interpretation: Neue Releases enthalten neue Funktionalität und tragen somit ein höheres Fehlerrisiko. Mit zunehmender Zeit reift die Anwendung, es kommen weniger neue Fehler hinzu und die Anwendung wird besser wartbar.
Bei der Darstellung von Produktivität und Qualität durch zwei getrennte Graphen werden ihre gegenseitigen Abhängigkeiten nicht deutlich. Anders, wenn Produktivität und Qualität als Dimensionen in einem X/Y-Diagramm aufgetragen werden:
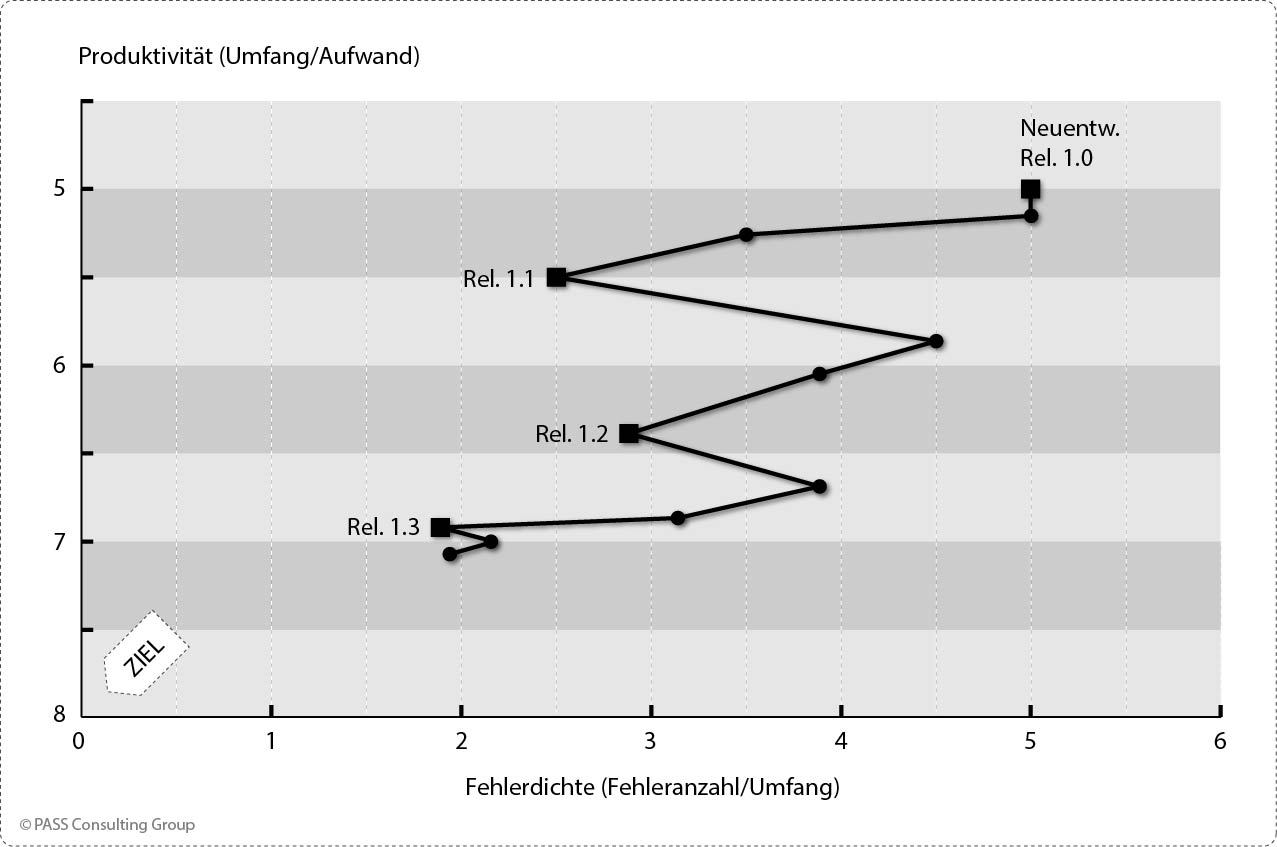
Ungeplante Einflüsse werden erkennbar
Viele ungeplante bzw. unerwartete Einflüsse werden erst durch die Visualisierung der zeitlichen Entwicklung von Produktivität und Qualität in einem X/Y-Diagramm deutlich. Das folgende Diagramm zeigt ein Fallbeispiel, bei dem ein neuentwickeltes System als Release 1.0 mit guter Produktivität (sieben DIP/PT) und schlechter Fehlerrate (zehn Fehler/kDIP) in Produktion gegeben wird. Mit den nachfolgenden Releases reduziert sich zwar die Fehlerrate sukzessive, sie zeichnen sich jedoch durch eine deutlich niedrigere Produktivität aus.
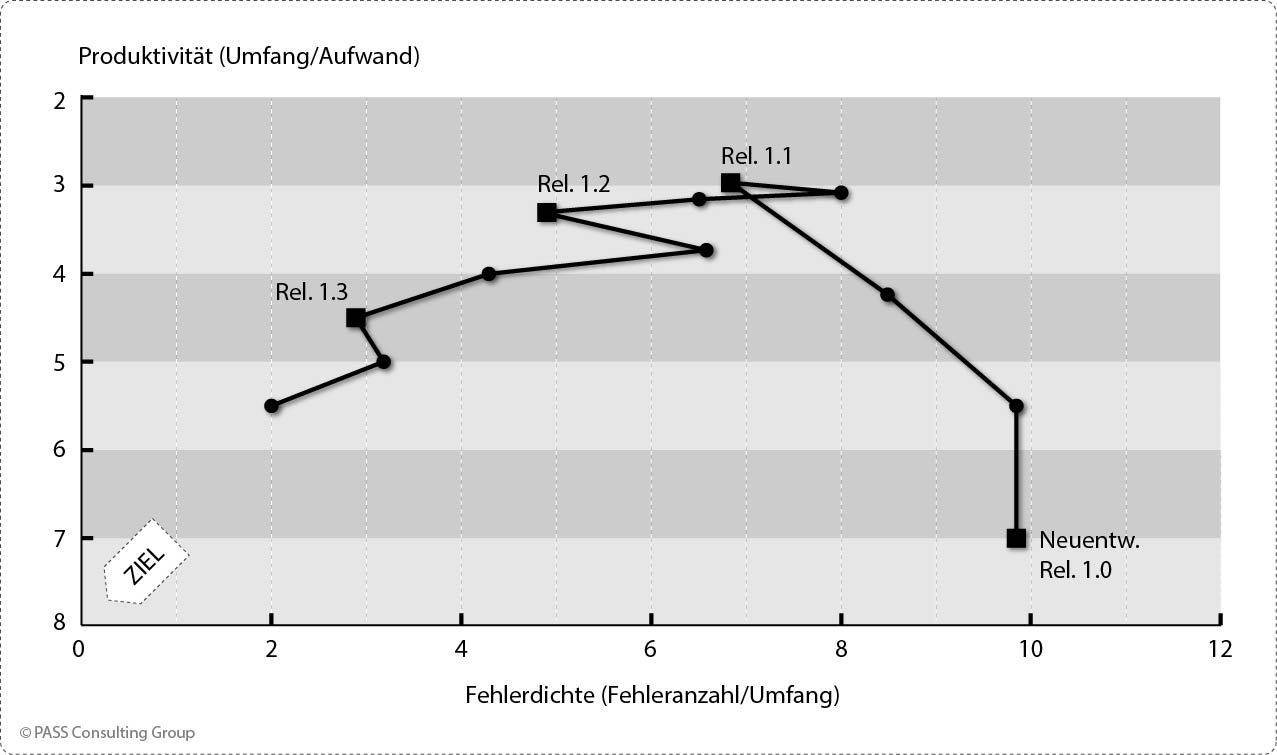
Zeitlicher Verlauf von Fehlerdichte und Produktivität bei vernachlässigter Qualitätssicherung, dargestellt in einem X/Y-Diagramm (Beispiel)[/caption]
Ein solcher Verlauf deutet darauf hin, dass im Rahmen der Neuentwicklung die analytische Qualitätssicherung vernachlässigt wurde. Der dadurch eingesparte Testaufwand bewirkt zunächst einen hohen Produktivitätswert. Letztendlich erfolgt der Test durch die ersten Nutzer des Systems, die eine hohe Anzahl an Fehlern feststellen. Der Aufwand zur Korrektur dieser zahlreichen Fehler fließt in die Produktivitätsmessungen der nächsten Releases ein und führt zu niedrigen Produktivitätswerten. Deutet ein solcher Verlauf der Messwerte auf verschleppte Qualitätssicherung hin und kann dies verifiziert werden, sind dringend Steuerungsmaßnahmen einzuleiten, denn einerseits entsteht bei den Nutzern des Systems ein schlechter Qualitätseindruck, andererseits sind die Gesamtkosten aufgrund der späten Fehlerkorrekturen in der Summe deutlich höher gegenüber angemessenen Tests vor der Produktivsetzung.
Das Fallbeispiel zeigt, dass eine einzelne punktuelle Messung der Produktivität sehr trügerisch sein kann. Über einen längeren Zeitraum betrachtet ist die Produktivität für dieses System plötzlich wieder niedrig. Erst eine Gegenüberstellung der Qualität liefert Indizien für die Ursache. Dringender Handlungsbedarf besteht, wenn sich die Kurve in einem solchen X/Y-Diagramm mit zunehmender Zeit nicht dem Zielbereich hoher Produktivität und guter Qualität annähert, sondern eher noch weiter davon entfernt. Eine solche Entwicklung kann darauf hindeuten, dass das System eingeschränkt wartbar ist und sich die Wartbarkeit zunehmend verschlechtert.
Sie wollen mehr erfahren? Der zweite Teil der Buchreihe „Produktivitätssteigerung in der Softwareentwicklung” beschäftigt sich intensiv mit der Analyse der Zeitverläufe von Produktivitäts- und Qualitätsmessungen, gibt Hinweise zu Analyseverfahren und zeigt anhand von Fallbeispielen mögliche Interpretationen auf.
Bildquelle: Shutterstock


